
|
|
|
|
What is Web 2.0? The thing about asking "What is Web 2.0"? is that the question is meaningless: there is no such thing as Web 2.0. Nevertheless, let you and I ask the question, as it will lead us into a fascinating journey, during which we will learn about new technology, complex new tools, the psychology of programmers, and — ultimately — something about ourselves. Are you ready? Web 2.0 is a contrived name, created by two companies, O'Reilly Media and MediaLive International, to promote a particular technology conference. The conference was held on October 5-7, 2004, in San Francisco. At the time, no one knew exactly what "Web 2.0" was supposed to mean, although there was a lot of speculation. The best guess was that Web 2.0 referred to something new, exciting and (possibly) lucrative. In the last few years, there have been significant changes in the Web: changes due to increased bandwidth, better browsers, sophisticated programming tools, and increased expectations. Could these changes be Web 2.0? To find out, let's ask: What's new, exciting and (potentially) lucrative on the Web? Before me start, let us observe that from our point of view, the Web hasn't actually changed much over the last five years. If you knew how to use the Web five years ago, you know how to use it now. If you knew what the Web looked like five years ago, you more or less know what it looks like now. Yes, there have been changes, but they have not been revolutionary compared to, say, the invention of the PC or the widespread availability of high bandwidth Internet connections. More important, as you will see, the nature of human beings, including programmers, has not changed at all. Having said all that, let's take a look at what is new on the Web, covering several categories: design, function, social services and programming tools.
Since 2005, you may have noticed that many Web sites have migrated to the same type of look. This is because Web site designers, like all designers, move in trendy waves of fashion. What is fashionable right now — what we might call the Web 2.0 look — is for designers to create complicated Web pages that pretend to be simple. More specifically: contemporary designers have fallen in love with grids consisting of large blocks. Using these blocks to carve out well-defined areas of the screen, the designers use bold logos, bold headings, and simple-looking sans serif fonts. (If you are a font person, think Arial Rounded, Helvetica, Vag Rounded, Myriad Pro, FF Meta, or Interstate.) The Web 2.0 colors are pastel-derived blends, ranging from neutral to bold. In Figure 1, you can see all the typical Web 2.0 colors. Below each color is its hexadecimal code. (You can ignore this if it doesn't mean anything to you.) What to be trendy? These are the colors to use. In Figure 2 you can see an example of a typical page. Does this type of look and feel seem familiar? Of course it does, it's Web 2.0! Figure 1: The most common Web 2.0 colors, with their hexadecimal codes. Look familiar?
|
|
Figure 2: A typical Web 2.0 page with all the clichés: the usual colors, deceptive simplicity, and blandness of content. 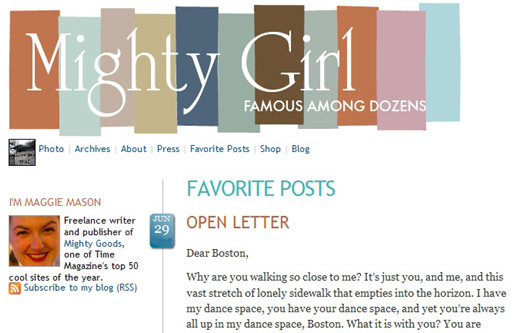
|
|
Figure 4: A sample spreadsheet created with Google's free online spreadsheet program. 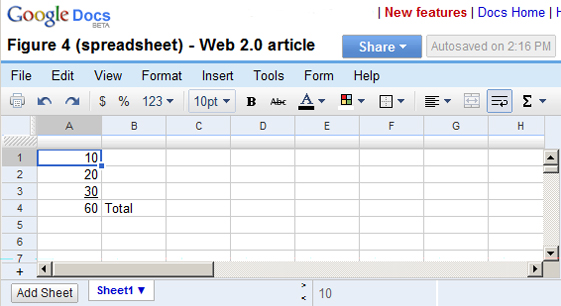
Figure 5: A sample document created with Google's free online word processor. 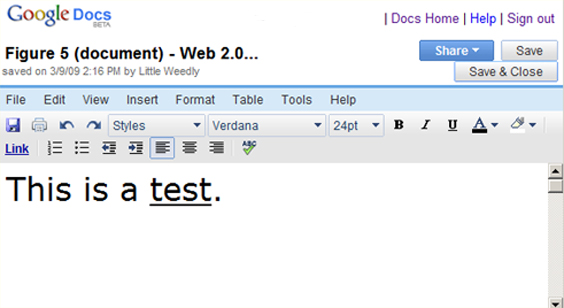
|
|
These are typical RIAs, so let's take a moment to analyze them by comparing them to more traditional programs, like Microsoft Excel (spreadsheets) and Microsoft Word (word processing). Excel and Word run in their own windows on your computer. The data you use resides on your computer or, at the very least, on your local network. Before you can use such a program you must pay for it and install it on your system. When a new version comes out, you must install the update before you can use it. With the Google applications, you do not pay for anything. The program and the storage are both free. In fact, this is the case with many Web-based applications: a leftover from the tech boom of the late 1990s, when it was thought that building market share was more important than earning a profit. (I will not comment on the long-term financial wisdom of such models.) Not only are Google services free, there is nothing to install: each time you use the application, it is downloaded to your computer automatically. Moreover, when a new version becomes available, there is nothing special for you to do. As a matter of course, whenever you use the program, the Google server sends you the latest version. Compared to Excel and Word, there are three obvious advantages to using the Google RIAs. First, they are free. Second, they are convenient. You can access your spreadsheets and documents from any computer at any time, without having to buy or install software. Moreover, you don't even have to worry about storing your data: Google does it for you, also for free. Finally, the Google RIAs make it easy to collaborate with other people. Any spreadsheet or document you create can be accessed by anyone else via a URL (if you give them permission). This means that anyone with a browser can look at and (with permission) modify your work. For most users, this is the most important feature of the entire system. As well as the Google applications work, there are several important disadvantages. First, compared to running your own program on your own computer, using an RIA is slow. This is only to be expected, as the application must be downloaded to your computer before you can run it. Even then, you are (in most cases) running a program that is interpreted, not compiled, which means it will be a lot slower than a native application. Finally, whenever you create or modify data, that data must be synchronized with a remote server, which takes time. Similarly, whenever your program needs anything from the server — a snippet of code, more information, whatever — the request must be passed to the server over the Internet and the data must be downloaded from the Internet, all of which, again, takes time. No matter how clever a system is constructed, when you run remote applications, network latency is always a problem. To make matters worse, the type of slowness you encounter is often the moment-to-moment slowness that is both irritating and — if you are a fast thinker — distracting. This is not unique to Google Docs & Spreadsheets or the Web. As a general rule, when you run an interpreted program within a restricted environment, there will always be a certain slowness. What you notice, as a user, is that your programs feel pokey and intermittently unresponsive. For example, for email, I use a program called Eudora, a standalone application that runs on my computer. It is rich with features and, because it runs locally, it is very responsive. When I compare the experience to using Web-based email, I notice a huge difference. True, if you use multiple computers, Web-based email is enormously convenient. However, compared to running your own mail program on your own computer, Web-based email is slow, clunky and primitive. The second disadvantage of RIAs is that you are not able to choose which version of the software you want to use. Whenever you connect to the Web site, the server will automatically send you the latest version, which means you are living in perpetual beta-land. In one sense, this is convenient. However, as I am sure you know, it is not always desirable to use the latest version of a program. In a business setting, where support is the most expensive part of maintaining computing systems, it makes sense to standardize on applications and specific versions, changing them rarely and only after careful evaluation. This is not possible when an outside vendor is sending your users whatever versions of its software it wants to send, regardless of your needs. Even in a personal setting, this is often the case. For example, on one of my computers, I use Microsoft Word 97 because it loads fast and does everything I want. There is no need for me to upgrade to a newer, more complicated, expensive, slower version of the same program. With most RIAs you don't have such choices. Although it seems nice that so many RIAs are free, experience shows us that, over time, as companies begin to recognize the need show a profit, free programs tend to become more and more commercial and more and more intrusive. (Compare, for example, the current versions of Acrobat Reader or RealPlayer with their early versions.) The third disadvantage to Web-based RIAs is that it makes it difficult for an IT department to control which applications its users are allowed to run. In the old days, companies could restrict the applications that were installed on their employees' computers. Today, RIAs can install themselves while an employee is browsing. Such programs operate beyond the control of the IT experts, the very people who are responsible for maintaining the corporate systems. This can create significant security and privacy problems. For example, do you want your employees creating spreadsheets that are stored on someone else's servers?
I mentioned earlier that the holy grail of today's Web programmers is to be able to run programs within a browser that are as powerful as traditional standalone applications. This not yet the case and perhaps it never will be. Still, many people want such programs and, to understand why, we need to look back at the history of business computing. In the 1960s, most computers were mainframe computers. Typically, they were IBM System/360 machines running OS/360. At the time, the main business use for computers was non-interactive data processing. By the late 1970s, many companies had started to use interactive time-sharing systems, either on mainframes or on minicomputers. However, it was a rare person who had his own computer. Psychologically, this was very important. When you shared a computer, you felt a connection to the system, as well as to the other users. This was particularly true when you used a terminal to access a time-sharing system. You could tell how many people were logged on by the subtle changes in response time. All this began to change in August 1981, when IBM introduced the IBM Personal Computer, the original PC. For the first time, companies could afford to furnish employees with their own computers. Having your own PC was wonderful, because it meant no more waiting: your computer was there to serve you and only you. However, it also meant that, for the first time, as a computer user, you were completely isolated. To appreciate how important this feeling can be, imagine yourself working alone in an office, using a PC connected to a large network or using a terminal connected to a time-sharing system. Even though you are physically alone, you still have a sense of being connected to something larger than yourself. Now compare this feeling to what you sense as you work in the same office, sitting in front of your very own PC, disconnected from the rest of the world. In general, people do not like to be isolated. In a prison, for example, one of the worst punishments is solitary confinement. Human beings need to feel connected and, it is this need, as much as hardware and software, that drives the creation of new technology (including, as we will see, Web 2.0). In the mid-1980s, for example, IT professionals were beginning to connect PCs into LANs (local area networks) which, in turn, could be connected into WANs (wide area networks). Within each network, one or more computers would run a network operating system, such as Novell Netware (introduced in 1983). The rational for using network servers was that they enabled users to share resources, most often disk storage and printers. This explanation, however, ignores the strong psychological components. Human beings do not like to be isolated: in order to thrive, they need to feel connected to other human beings. As you may have heard, the early LANs were a lot of trouble to build and maintain, but as much trouble as they were, they were very important: not only because they allowed file and print sharing, but because the reestablished a connection between individual users. What does this have to do with Web 2.0? Consider again the Google Docs & Spreadsheets RIAs we discussed earlier. Evaluated fairly, it is easy to see that the actual applications are significantly inferior and slower than conventional word processing and spreadsheet programs. So, aside from price, why are the Google programs so popular? Because when you use them, you feel connected to a large system (the Internet) and when you collaborate, you feel connected to other people. Take a look at other important Web 2.0 applications, and you will find the same thing. Technology may influence what we can do but, more than we realize, what we create is driven by our nature and our biological needs.
There are a great many Web 2.0 RIAs (rich Internet applications), far more than we have time to discuss. What I want you to understand, however, is the technology behind such applications. In other words, what type of tools enable programmers to build RIAs? Before we get to that topic, I want to take a few moments to lay the groundwork. To do so, I will talk about the two most popular Web 2.0 RIAs: blogs and social networking services. A blog is a Web site featuring journal entries written by one or more people. (The name blog comes from the term "Web log".) A typical blog has four characteristics. 1. Postings are displayed in reverse chronological order (newest first), so it's easy to see what's new. 2. A reader can leave comments of his or her own. This allows anyone to respond to the opinions of the blogger and to the comments of other readers. 3. There are links to other Web pages, most often to other blogs and to information related to the topic under discussion. 4. It is possible to subscribe to the blog via a Web feed (the old name was "RSS feed"). This allows you to use a "feed reader" to keep up on what's new with the blog. The feed reader can be a standalone program or can be integrated into an online site for which you have an account. Figure 6 shows a typical set of buttons from a blog that allows you to use RSS (Real Simple Syndication) to subscribe to the blog via your favorite online site. Figure 6: A typical set of buttons allowing a reader to initiate a free RSS (Real Simple Syndication) subscription. 
Although online diaries have been around for a long time, blogging as we know it today only became popular in the late 1990s. Since then, the number of people who blog has increased enormously. For example, as I write this, the Web site Technorati (a blog search engine) claims to track 112.8 million different blogs. Just as interesting, at the end of 1997, there were over 73 millions blogs just in China. Most blogs are simply words (plain text), sometimes annotated with images. However, there are specialized blogs that enable people to share various types of data. For example, there are photoblogs (for sharing photographs), vlogs (videos), and podcasts (audio files). The totality of all blogs is sometimes referred to, misleadingly, as the "blogosphere". There are hundreds of millions of people who participate in the blogosphere, most of whom are casual readers or bloggers, and who care little about who is doing what. Among the hard-core bloggers, however, there is a definite pecking order: the more people who read your blog, the more important you are. Since readership is hard to measure, the coin of the realm is links: the more blogs that link to your blog, the more important you are. To a great many bloggers, such numbers are very important. In the popular press, the importance of blogging is exaggerated beyond all proportion. This is easy to see in two different ways. First, the mainstream media — newspapers, magazines, TV, radio — give disproportionate credit to bloggers, who are often portrayed as populist heroes who can change reality just by writing about it. This is a very Web 2.0 idea. Second, the online world has adopted the idea that whatever the average Joe or Jane has to say about current affairs is just as important as the opinions of experts or professional commentators. For example, many newspaper Web sites invite readers to write their own comments regarding news stories, features and editorials. In principle, this seems like a good idea: at least until you spend some time reading such comments. The belief that the opinion of anyone with access to a keyboard is as valuable and interesting as the commentary of professional politicians, scientists, researchers, professors and teachers is also a very Web 2.0 idea. Because most blogs are neither censored nor edited, they reflect the intellect and skill (or lack thereof) of the person doing the writing. As you would imagine, hardly any blogs are worth reading. Perhaps the best way to understand blogging is to recall the words of the musician/humorist Tom Lehrer commenting on a related topic, folk songs: "The reason most folk songs are so atrocious," he observed, "is that they were written by the people."
The first social networking site, Classmastes.com, was created in 1995 as a tool to help people find old schoolmates. Since then, modern social networking has developed into a large number of sophisticated Web-based services. Indeed, today, there are several hundred such sites, the most well-known being MySpace, Facebook, Orkut (sponsored by Google), Friendster, and Xanga. Many social networking sites also offer blogging facilities. For example, MySpace and Xanga each host tens of millions of blogs. (Think about that for a moment). MySpace, in fact, is one of the most popular Web sites in the world. The question that comes to mind is: What is social networking, and why do we need it? A social networking site combines a specialized search engine with user-generated content. When you join such a site, you create a "profile". A typical profile will have your name (real or not), photos, information about you, and links to other profiles. If someone links to you they are called your "friend". On most social networking sites, the unwritten goal is to acquire as many "friends" as possible. (This is similar to the goal of many bloggers, who want as many links to their blog as possible.) Fifty "friends" would be a lot; 150 would be exceptional. So what do people do on social networking sites? Four things. First, some people actually look for real friends. Indeed, there are many people who have met their boyfriends and girlfriends in this way. Second, a relatively small number of people look for information, music, videos, and so on. MySpace, for example, has a great many profiles created by organizations offering information about music groups, businesses, services, etc. Perhaps the most unexpected are the U.S. Marine Corps and U.S. Army, both of which have MySpace profiles. (As I write this, the Marine Corps has 77.052 "friends"; the Army, has 87,299 "friends".) Third, people use social networking sites to look for other people with common interests. For example, there are business sites devoted to "networking", where you can search for job opportunities, look for people to hire, post your own business profile, and so on. By far, however, the most popular activity on these sites is simply hanging out, a pastime which is difficult to explain if you have never done it. When you "hang out" in person, you go somewhere, stand near other people, and chat mindlessly. Hanging out online at a social networking site is different. It requires you to spend hours of your time looking at other people's profiles, reading their blogs, viewing photos and videos, inviting other people to be your "friend", and possibly IMing (instant messaging) various acquaintances. From time to time, you might add to your own profile, write something in your blog, or upload your own photos, music or videos. If this doesn't sound like much of a life to you, I agree. And yet, hundreds of millions of people around the world — most of them teenagers or younger — hang out on social networking sites. I have met teenagers who will sit in front of their laptops for hours at a time, just hanging out on MySpace. Why would anyone want to do this? The truth is, no matter how independent we may feel, from time to time, we all need to connect to other people. This is especially true for teenagers, who have particularly demanding social needs. In the absence of satisfying, face-to-face relationships, hanging out at a social networking site is one way for people to feel they are meeting their needs. What a Web 2.0-thing to do!
In the old days (the 1990s), the Web was a relatively simple client-server system. Your browser was your client. When you entered a Web address or when you clicked on a link, your browser would contact the appropriate server and ask for a Web page. The server would then send the page to your browser. The page would consist of content — mostly text and images — embedded in HTML. Your browser would interpret the HTML and render the page, which it would then display for you. Today, this same system still exists. However, modern browsers and servers are much more complex and Web-based functionality has increased enormously beyond simple HTML. Indeed, as we discussed earlier, the power of the Web has increased to the point where it is now possible to run sophisticated programs called RIAs (rich Internet applications) within a browser. There are many different systems for creating, running and servicing RIAs. One thing they all have in common is an intermediate layer of code, often referred to as a client engine. The client engine, which is downloaded from the server, sits between the user and the server, and provides extra functionality not supplied by the browser. Typically, a client engine is downloaded when the RIA starts. However, it is common for parts of the client engine, as well as much of the data, to be downloaded in pieces, over time. In this way, the application relies upon asynchronous communication with the server, making for increased efficiency and, from the user's point of view, better response time. Most important, it allows the application to react appropriately as the user's needs change from one moment to the next. I caution you not to see this paradigm as being new. Since the 1960s, there have been swings, back and forth, between computing locally (at the client, in today's terminology) and computing remotely (at the server). As hardware becomes faster and cheaper, there is a tendency to do more computing on the user's machine. As bandwidth becomes faster and cheaper, the trend moves towards computing on a remote machine. Still, no matter how fast the bandwidth, local computing is always faster than remote computing, because network latency is always a factor. Perhaps you have some experience with network applications or with X Window programs in which users work with "thin clients". In such systems, most of the code and data is kept on a server. This may sound familiar, as well it should. The concept of the RIA is nothing more than a new type of thin client system. The difference is that the server is no longer on a local network: instead, it can be anywhere on the Internet. As you might imagine, developing a RIA is much more difficult than developing an equivalent desktop application. Imagine what is involved in writing a program that must install itself and then run within any browser, under any operating system, on any kind of hardware platform. Imagine how difficult it is to test and debug such applications effectively As I mentioned, there are many different systems for creating and maintaining RIAs. To give you a feeling for how they work, we'll talk about one of them in detail: a system known as Ajax.
Ajax is one of many systems used to create RIAs. The term coined in February 2005 by a programmer named Jesse James Garrett. Garrett wanted a name to describe a set of tools he was using to create interactive Web pages and Web-based applications. Today, a typical set of Ajax tools would be as follows (I'll explain the details in a moment): • XHTML and CSS for presentation of data • the DOM for dynamic display and interaction • XMLHttpRequest for asynchronous data retrieval • XML for data interchange and manipulation • JavaScript for connecting everything together (Although Garrett never meant for Ajax to be an acronym, you can think of it as meaning "Asynchronous JavaScript and XML".) Under the old HTML-driven system, whenever a user requested a change, the entire Web page would need to be reloaded. To a user, this would feel slow and relatively unresponsive. With Ajax and similar technologies, the client and server are able to exchange data behind the scenes, which allows a Web page to be dynamic and responsive. To give you an idea how this all works, let's go over each of the components in turn. First, as with all Web-based systems, the presentation of data is based on HTML. In this case, the markup language as actually XHTML, an alternative to HTML, just as powerful but with a stricter syntax. (Technically, HTML is an application of SGML, a metalanguage used to define markup languages; XHTML is an application of XML, a standardized, general-purpose markup language. The acronyms are as follows. HTML = Hypertext Markup Language; SGML = Standard Generalized Markup Language; XML = Extensible Markup Language; and XHTML = Extensible Hypertext Markup Language.) To enhance the presentation of the data, CSS (cascading stylesheets) is used. CSS is a stylesheet language that specifies exactly how the various elements of a Web page should be displayed. The next component of Ajax is the DOM or Document Object Model. The DOM is an API (application programming interface) that enables a programmer to refer to HTML or XML elements as objects. Specifically, the DOM creates an object-oriented model of an HTML or XML document as a tree in which each node represents a specific element or attribute. Under the auspices of the API, a programmer can use a variety of methods to manipulate individual HTML or XML elements on the fly. For example, a program can create new elements, insert new text, delete existing text, move any part of the document from one place to another, and so on. The next part of the toolkit is XMLHttpRequest, an API based on a concept originally developed by Microsoft for Outlook Web Access 2000. This API allows dynamic communication between the client engine, running on the user's computer, and the remote server. In this way, XMLHttpRequest is the component that makes possible asynchronous communications between the client engine and the server. Although XMLHttpRequest can be used to request any type of data, it is typically employed to access a back-end database residing on the server. With most systems, data is returned in XML format. However, you will also see other formats used, in particular, HTML, JSON (JavaScript Object Notation), and even plain text. The glue that holds an Ajax system together, of course, is the program that provides the inner workings of the client engine. For many applications, the language of choice is JavaScript. JavaScript is a widely used scripting language. The original version was released in 1995 by Netscape Communications Corporation and Sun Microsystems for use with the Netscape browser. Modern JavaScript is an implementation of ECMASCript, a standardized scripting programming language. (ECMA, originally the European Computer Manufacturers Association, is an international standards organization.) Despite the name, JavaScript has nothing to do with the Java programming language. Rather, JavaScript is a prototype-based scripting language with a C-like syntax. (Quick digression: With traditional class-based object-oriented programming, you create a class and then use it to create instances of objects. With a prototype-based language, you don't use classes. Rather you create objects as you need them. When you want similar objects, you "clone" them. If you want slightly different objects, you modify the clones.) JavaScript can be used for a large variety of tasks, and JavaScript interpreters are provided within many environments. In particular, JavaScript is supported by all the major browsers and, as such, it has become the most popular and useful Web-based programming language. JavaScript is widely used for two reasons. First, it readily lends itself to creating prototypes quickly. Second, it is easy for anyone, even a non-programmer, to add functionality to a Web page by embedding snippets of JavaScript code within the HTML. For our purposes, we recognize JavaScript as the most widely used programming language on the client side of RIAs. As such, it is the glue that holds together most Ajax applications. To summarize: Imagine a group of programmers and designers working together to create a Web-based RIA. They use XHTML to create the Web pages and CSS to control presentation of the data. They use the DOM (Document Object Model) to get at the various parts of the HTML or XML document, in order to make changes dynamically as conditions warrant. They use the XMLHttpRequest API to retrieve data asynchronously from back-end databases or other servers. They use XML to exchange and manipulate data. And, to tie it all together, they use JavaScript to write the client-side scripts. As you can imagine, it is very difficult to write complex, bug-free Ajax applications. Still, that doesn't stop many, many companies from spending a lot of money trying to do so. How Web 2.0 can you get?
When we realize that something is important but we don't really understand it, we make up a name for it. This allows us to talk about it, which is good. It also allows us to pretend that we understand it, which is not so good. Although the term "Web 2.0" was created for marketing a particular conference, the name has attached itself to all that is new and interesting on the Web. So what is Web 2.0? One the one hand, it's nothing: there is no such thing. On the other hand, Web 2.0 refers to a large variety of new technologies, as well as their social and economic ramifications. Interpreted in this way, Web 2.0 is a broad term that covers: 1. The current trends of Web page design, including fonts, colors, layout and user interaction. 2. Web-based programs that compete with traditional standalone applications. 3. The increasing, but still unsatisfying, feeling of connection we have when we use such programs. 4. An environment in which anyone can express their opinion in a public venue, and the assumption that such opinions are valuable. 5. Free services that offer the promise of personal communication to massive numbers of users. 6. Web-based systems used by businesses to communicate with their users and with other businesses. 7. The large number of complex, powerful and imperfect tools used to create such systems. Not bad for something that doesn't really exist.
If you want to explore the ideas we discussed in this essay, here are some resources you will find interesting: Web 2.0 http://en.wikipedia.org/wiki/Web_2.0 How to bluff your way in Web 2.0
http://www.centernetworks.com/sxsw-panel-how-to-bluff- Read how Tim O'Reilly, CEO of O'Reilly Media has to say as he tries to define "Web 2.0". Tim is the CEO of O'Reilly Media, a cosponsor of the original Web 2.0 Conference in October 2004. Tim is a very smart guy, and it speaks volumes that he can't explain the very idea he help create, without confusing everyone in the room:
http://www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/ Google docs & spreadsheets Blogs http://en.wikipedia.org/wiki/Blog Social Networking
http://en.wikipedia.org/wiki/Social_network_service
RSS (Web feeds)
http://www.creative-weblogging.com/50226711/what_is_rss.php
Miltary Myspace pages
U.S. Army: http://www.myspace.com/army
DOM (Document Object Model)
http://www.w3.org/TR/DOM-Level-2-Core/introduction.html
© All contents Copyright 2025, Harley Hahn
|