Harley Hahn's Guide to
Unix and Linux
|
|
Harley Hahn's Guide to
|
|
A Personal Note
Chapters...
Command
INSTRUCTOR |
Chapter 23... The Unix Filesystem
In the next three chapters, we will talk about the Unix filesystem, the part of the operating system that serves you and your programs by storing and organizing all the data on your system. In this chapter, we will cover the basic concepts. We will then discuss the details of using directories in Chapter 24 and using files in Chapter 25. The goal of this chapter is to answer three key questions. First, what is a Unix file? As you might imagine, a file can be a repository of data stored on a disk. However, as you will see, there is a lot more to it than that. The second question involves organization. It is common for a Unix system to have hundreds of thousands of files. How can so many items be organized in a way that makes sense and is easy to understand? Finally, how is it possible for a single unified system to offer transparent support of many different types of data storage devices? The discussion begins with a simple question that has a surprisingly complex answer: What is a file?
In the olden days, before computers, the term "file" referred to a collection of papers. Typically, files were kept in cardboard folders, which were organized and stored in filing cabinets. Today, most data is computerized, and the definition of a file has changed appropriately. In its simplest sense, a file is a collection of data that has been given a name(*). Most of the time, files are stored on digital media: hard disks, CDs, DVDs, floppy disks, flash drives, memory cards, and so on. * Footnote A Unix file can actually have more than one name. We'll talk about this idea in Chapter 25 when we discuss links. Within Unix, the definition of a file is much broader. A FILE is any source, with a name, from which data can be read; or any target, with a name, to which data can be written. Thus, when you use Unix or Linux, the term "file" refers not only to a repository of data like a disk file, but to any physical device. For example, a keyboard can be accessed as a file (a source of input), as can a monitor (an output target). There are also files that have no physical presence whatsoever, but accept input or generate output in order to provide specific services. Defining a file in this way — with such generality — is of enormous importance: it means that Unix programs can use simple procedures to read from any input source and write to any output target. For example, most Unix programs are designed to read from standard input and write to standard output (see Chapters 18 and 19). From the programmer's point of view, I/O (input/output) is easy, because reading and writing data can be implemented in a simple, standard way, regardless of where the actual data is coming from or going to. From the user's point of view, there is a great deal of flexibility, because he can specify the input source and output target at the moment he runs the program. As you might imagine, the internal details of the Unix filesystem — or any filesystem — are complex. In this chapter, we will cover the basic concepts and, by the time we finish, you will find that the Unix filesystem is a thing of compelling beauty: the type of beauty you find only in complex systems in which everything makes sense.
There are many different types of Unix files, but they all fall into three categories: ordinary files, directories, and pseudo files. Within the world of pseudo files, there are three particular types that are the most common: special files, named pipes, and proc files. In this section, we'll take a quick tour of the various most important types of files. In the following sections, we'll discuss each type of file in more detail. An ORDINARY FILE or a REGULAR FILE is what most people think of when they use the word "file". Ordinary files contain data and reside on some type of storage device, such as a hard disk, CD, DVD, flash drive, memory card, or floppy disk. As such, ordinary files are the type of file you work with most of the time. For example, when you write a shell script using a text editor, both the shell script and the editor program itself are stored in ordinary files. As we discussed in Chapter 19, there are, broadly speaking, two types of ordinary files: text files and binary files. Text files contain lines of data consisting of printable characters (letters, numbers, punctuation symbols, spaces, tabs) with a newline character at the end of each line. Text files are used to store textual data: plain data, shell scripts, source programs, configuration files, HTML files, and so on. Binary files contain non-textual data, the type of data that makes sense only when executed or when interpreted by a program. Common examples are executable programs, object files, images, music files, video files, word processing documents, spreadsheets, databases, and so on. For example, a text editor program would be a binary file. The file you edit would be a text file. Since almost all the files you will encounter are ordinary files, it is crucial that you learn basic file manipulation skills. Specifically, you must learn how to create, copy, move, rename, and delete such files. We will discuss these topics in detail in Chapter 25. The second type of file is a DIRECTORY. Like an ordinary file, a directory resides on some type of storage device. Directories, however, do not hold regular data. They are used to organize and access other files. Conceptually, a directory "contains" other files. For example, you might have a directory named vacation within which you keep all the files having to do with your upcoming trip to Syldavia. A directory can also contain other directories. This allows you to organize your files into a hierarchical system. As you will see later in the chapter, the entire Unix filesystem is organized as one large hierarchical tree with directories inside of directories inside of directories. Within your part of the tree, you can create and delete directories as you see fit. In this way, you can organize your files as you wish and make changes as your needs change. (You will recall that, in Chapter 9, during our discussion of the Info system, we talked about trees. Formally, a TREE is a data structure formed by a set of nodes, leaves, and branches, organized in such a way that there is, at most, one branch between any two nodes.) You will sometimes see the term FOLDER used instead of word "directory", especially when you use GUI tools. The terminology comes from the Windows and Macintosh worlds, as both these systems use folders to organize files. A Windows folder is a lot like a Unix directory, but not as powerful. A Macintosh folder is a Unix directory, because OS X, the Mac operating system, runs on top of Unix (see Chapter 2). The last type of file is a PSEUDO FILE. Unlike ordinary files and directories, pseudo files are not used to store data. For this reason, the files themselves do not take up any room, although they are considered to be part of the filesystem and are organized into directories. The purpose of a pseudo file is to provide a service that is accessed in the same way that a regular file is accessed. In most cases, a pseudo file is used to access a service provided by the kernel, the central part of the operating system (see Chapter 2). The most important type of pseudo file is the SPECIAL FILE, sometimes called a DEVICE FILE. A special file is an internal representation of a physical device. For example, your keyboard, your monitor, a printer, a disk drive, in fact, every device in your computer or on your network — they can all be accessed as special files. The next type of pseudo file is a NAMED PIPE. A named pipe is an extension of the pipe facility we discussed in Chapter 15. As such, it enables you to connect the output of one program to the input of another. Finally, a PROC FILE, allows you to access information residing within the kernel. In a few specific cases, you can even use proc files to change data within the kernel. (Obviously, this should be done only by very knowledgeable people.) Originally, these files were created to furnish information about processes as they are running, hence the name "proc". What's in a Name? File When you see or hear the word "file", you must decide, by context, what it means. Sometimes it refers to any type of file; sometimes it refers only to files that contain data, that is, ordinary files. For example, suppose you read the sentence, "The ls program lists the names of all the files in a directory." In this case, the word "file" refers to any type of file: an ordinary file, a directory, a special file, a named pipe, or a virtual file. All five types of files can be found in a directory and, hence, listed with the ls program. However, let's say you read, "To compare one file to another, use the cmp program." In this case, "file" refers to an ordinary file, as that is the only type of file that contains data that can be compared.
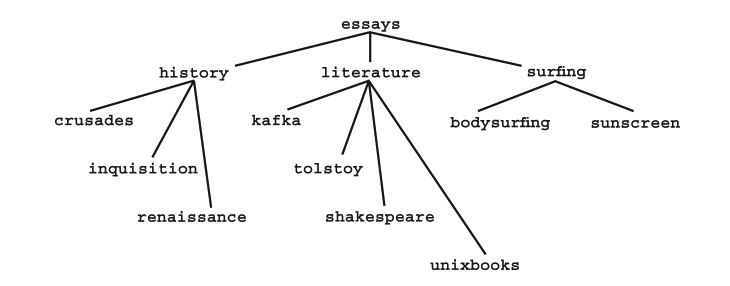
We use directories to organize files into a hierarchical tree-like system. To do so, we collect files together into groups and store each group in its own directory. Since directories are themselves files, a directory can contain other directories, which creates the hierarchy. Here is an example. You are a student at a prestigious West Coast university and you are taking three classes — History, Literature and Surfing — for which you have written a number of essays. To organize all this work, you make a directory called essays (don't worry about the details for now). Within this directory, you create three more directories, history, literature and surfing, to hold your essays. Each essay is stored in a text file that has a descriptive name. Figure 23-1 shows a diagram of what it all looks like. Notice that the diagram looks like an upside-down tree. |
|
A PARENT DIRECTORY is one that contains other directories. A SUBDIRECTORY or CHILD DIRECTORY is a directory that lies within another directory. In Figure 23-1, essays is a parent directory that contains three subdirectories: history, literature and surfing. It is common to talk about directories as if they actually contain other files. For example, we might say that essays contains three subdirectories and literature contains four ordinary files. Indeed, you might imagine that if you could look inside the literature directory, you would actually see the four files. Actually, all files are stored as separate entities. A directory does not hold the actual files. It merely contains the information Unix needs to locate the files. You, however, don't need to worry about the details, as Unix maintains the internal workings of the entire filesystem automatically. All you have to do is learn how to use the appropriate programs, and Unix will do whatever you want: make a directory, remove a directory, move a directory, list the contents of a directory, and so on. We'll cover these programs in Chapter 24.
Special files are pseudo files that represent physical devices. Unix keeps all the special files in the /dev (device) directory. (We'll talk about the slash at the beginning of the name later in the chapter.) To display the names of the special files on your system, use the ls program (Chapter 24) as follows: ls /dev | less You will see many names, most of which you will rarely need to use. This is because, for the most part, special files are used by system programs, not users. Still, there are a few special files that are interesting to know about. I have listed these files in Figure 23-2, and we will discuss them in three different groups: hardware, terminals, and pseudo- devices. Figure 23-2: The most interesting special files Special files are pseudo files that are used to represent devices. Such files are mostly used by system programs. Although you will rarely use special files directly, there are a few that it is interesting to know about. See text for details.
If you are interested in understanding the names of other special files, there is an official master list that can help you. To find this list, search on the Web for "LANANA Linux Device List". (LANANA stands for "Linux Assigned Names and Numbers Authority".) As the name implies, this list is specifically for Linux. However, most of the important special files have similar names on all Unix systems, so the list is useful even if you don't use Linux.
All devices connected to the computer are accessible via special files. Let's start with the most straightforward devices, the ones that represent actual hardware. As you can see in Figure 23-2, the file /dev/fd0 represents a floppy disk drive. The number at the end of a device name refers to a specific device. In this case, /dev/fd0 refers to the first floppy disk drive. (Computer programmers often start counting at zero.) If there is a second floppy drive, it would be /dev/fd1, and so on. Similarly, /dev/lp0 corresponds to the first printer. Hard disks are handled a bit differently. The first IDE hard disk is referred to as /dev/hda, the second is /dev/hdb, and so on. Hard drives are organized into one or more PARTITIONS, which act as separate devices. The first partition of the first hard disk is referred to as /dev/hda1. If there is a second partition, it is /dev/hda2. SCSI and SATA hard drives have their own names. The first SCSI or SATA drive is /dev/sda, the second is /dev/sdb, and so on. Again, partitions are numbered, so the first partition on the first SCSI or SATA drive would be /dev/sda1. The SCSI designations are sometimes used for other types of devices as well. A common example is USB flash memory, which is treated as if it were a removable SCSI disk. For this reason, the name of the special file for flash memory will be named /dev/sda1 or something similar.
In Figure 23-2 you will notice several different special files that represent terminals. Here is why. In the olden days, terminals were separate physical devices that were connected to a host computer (see Chapter 3). Such terminals were represented by special files named /dev/tty1, /dev/tty2, and so on. (As I explained in Chapter 7, the abbreviation TTY is a synonym for terminal. This is because the very first Unix terminals were Teletype machines, which were referred to as TTYs.) The /dev/tty naming convention is still used today for terminals that act like hardware devices. In particular, this is the case when you run Unix in single-user mode. Your keyboard and monitor (the console) act as a built-in text-based terminal. The special file that represents this terminal is /dev/tty1. Similarly, when you use a virtual console within a desktop environment (see Chapter 6), it too acts like an actual terminal. By default, Linux supports six such consoles, which are represented by the special files /dev/tty1 through /dev/tty6. Everything is different, however, when you use a GUI to run a terminal emulation program within a window. Because there isn't an actual terminal, Unix creates what we call a PSEUDO TERMINAL or PTY to simulate a terminal. PTYs are used when you open a terminal window within a GUI (Chapter 6), and when you connect to a remote Unix host (Chapter 3). In both cases, the PTY acts as your terminal. It happens that there are two different systems for creating pseudo terminals, so you will see two types of names. If your version of Unix uses the first system, the special files that represent pseudo terminals will have names like /dev/ttyp0 and /dev/ttyp1. If you use the other system, the names will be /dev/pts/1, /dev/pts/2, and so on. You can see both types of names in Figure 23-2. At any time, you can display the name of your terminal by using the tty program. For example, let's say you are working at virtual terminal #3. You enter: tty The output is: /dev/tty3 For convenience, the special file /dev/tty represents whichever terminal you are currently using. For example, if you are using virtual console #3, /dev/tty is the same as /dev/tty3. Here is an example of how you can use a special file. As you will see in Chapter 25, you use the cp program to make a copy of a file. In Chapter 11, we talked about the password file, /etc/passwd. Let's say you want to make a copy of the password file and call the copy myfile. The command to do so is: cp /etc/passwd myfile That only makes sense. Now consider the following command: cp /etc/passwd /dev/tty This copies the password file to your terminal. The effect is to display the contents of the file on your monitor. Try it — then take a moment to think about what happened.
The last type of special file we will discuss is the PSEUDO-DEVICE. A pseudo-device is a file that acts as an input source or output target, but does not correspond to an actual device, either real or emulated. The two most useful pseudo-devices are the NULL FILE and the ZERO FILE. The null file is /dev/null; the zero file is /dev/zero. Any output that is written to these devices is thrown away. For this reason, these files are sometimes referred to whimsically as "bit buckets". We discussed the null file in detail in Chapter 15. Here is an example from that chapter. Let's say you have a program named update that reads and modifies a large number of data files. As it does its work, update displays statistics about what is happening. If you don't want to see the statistics, you can redirect standard output to either of the bit buckets:
update > /dev/null
If you want to experiment, here is a quick example you can try for yourself right now. Enter the command: cat /etc/passwd You will see the contents of the password file. Now, redirect the output of the cat command to either the null file or the zero file. Notice that the output vanishes:
cat /etc/passwd > /dev/null
When it comes to output, the two bit buckets work the same. The only difference is what happens when they are used for input. When a program reads from /dev/null, no matter how many bytes of input are requested, the result is always an eof signal (see Chapter 7). In other words, reading from /dev/null returns nothing. When a program reads from /dev/zero, the file generates as many bytes as are requested. However, they all have the value 0 (the number zero). In Unix, this value is considered to be the NULL CHARACTER or, more simply, a NULL. As strange as seems, a constant source of null characters can be useful. For instance, for security reasons, it is often necessary to wipe out the contents of a file or an entire disk. In such cases, you can overwrite the existing data with nulls simply by copying as many bytes as necessary from /dev/zero to the output target. (The terminology is a bit confusing: the null file returns nothing, while the zero file returns nulls. Such is life.) Below is an example in which we use dd to create a brand new file completely filled with null characters. (The dd program is a powerful I/O tool which I won't explain in detail. If you want more information, see the online manual.) dd if=/dev/zero of=temp bs=100 count=1 In this example, if is the input file; of is the output file; bs is the block size; and count is the number of blocks. Thus, we copy a 100-byte block of data from /dev/zero to a file named temp. If you want to experiment with this example, run the dd command and then display the contents of temp with the hexdump or od programs (Chapter 21). When you are finished, you can remove temp by using the rm program (Chapter 25). The final two pseudo-devices, /dev/random and /dev/urandom, are used to generate random numbers. Thus, whenever a program needs a random number, all it has to do is read from one of these files. It may be that you are one of those odd people who do not use random numbers much in your personal life. If so, you may wonder why they are important. The answer is that mathematicians and scientists use such numbers to create models of natural processes that involve chance. When used in this way, an unlimited, easy-to-use source of random numbers is invaluable. (If this sort of thing interests you, read a bit about "stochastic processes".) Random numbers are also used by programs that generate cryptographic keys for encrypting data. — technical hint — Unix and Linux provide two different special files to generate random numbers: /dev/random and /dev/urandom. The difference is subtle, but important, when complete randomness is essential. Computerized random number generators gather "environmental noise" and store it in an "entropy pool". The bits in the entropy pool are then used to generate random numbers. If the entropy pool runs out, the /dev/random file will stop and wait for more noise to be gathered. This ensures complete randomness for crucial operations, such as creating cryptographic keys. However, at times, there can be a delay if it is necessary to wait for the entropy pool to fill. The /dev/urandom file, on the other hand, will never stop generating numbers even when the entropy pool is low (u stands for "unlimited). Instead, some of the old bits will be reused. In theory, data that is encrypted using low-entropy random numbers is slightly more susceptible to attack. In practice, it doesn't make much difference, because no one actually knows how to take advantage of such a tiny theoretical deficiency(*). Still, if you are paranoid, using random instead of urandom may help you sleep better. If not, urandom will work just fine, and it will never make you wait. * Footnote At least in the non-classified literature.
A named pipe is a pseudo file used to create a special type of pipe facility. In this way, named pipes act as an extension to the regular pipe facility we discussed in Chapter 15. Before I show you how they work, let's take a quick look at a regular pipeline. The following command extracts all the lines in the system password file that contain the characters "bash". The data is then piped to the wc program (Chapter 18) to count the number of lines: grep bash /etc/passwd | wc -l When we use a pipe in this way, it does not have a specific name: it is created automatically and it exists only while the two processes are running. For this reason, we call it an ANONYMOUS PIPE. A named pipe is similar to an anonymous pipe in that they both connect the output of one process to the input of another. However, there are two important differences. First, you must create a named pipe explicitly. Second, a named pipe does not cease to exist when the two processes end: it exists until it is deleted. Thus, once you create a named pipe, you can use it again and again. You will often see a named pipe referred to as a FIFO (pronounced "fie-foe"), an abbreviation for "first-in, first-out". This is a computer science term used to describe a data structure in which elements are retrieved in the same order they went in. More formally, such a data structure is called a QUEUE.(*) * Footnote Compare to a stack (see Chapters 8 and 24), a data structure in which elements are stored and retrieved in a LIFO ("last in, first out") manner. To create a named pipe, you use the mkfifo (make FIFO) program. The syntax is: mkfifo [-m mode] pipe where mode is a file mode of the type used with the chmod program; and pipe is the name of the pipe you want to create. (We'll discuss file modes in Chapter 25 when we talk about chmod; for now, you can ignore the -m option.) Most of the time, named pipes are used by programmers to facilitate the exchange of data between two processes, an operation called INTERPROCESS COMMUNICATION or IPC. In such cases, a program will create, use, and then delete named pipes as necessary. Using the mkfifo program, you can create a named pipe by hand from the command line. It isn't done much, but let me show you an example, so you can experiment on your own to get a feeling for how it all works. In order to do the experiment, you will need to open two terminal windows or use two virtual consoles. Then type the following command into the first terminal window. This command uses mkfifo to create a named pipe called fifotest: mkfifo fifotest Now, let's send some input to the pipe. In the same window, enter the following command to grep the system password file for lines containing "bash" and redirect the output to fifotest: grep bash /etc/passwd > fifotest Now move to the second terminal window or virtual console. Enter the following command to read the data from the named pipe and count the number of lines. As soon as you enter the command, the wc program reads from the named pipe and displays its output. wc -l < fifotest Once you are finished with the named pipe, you can delete it by using the rm (remove) program: rm fifotest Obviously, this was a contrived example. After all, we accomplished the very same thing a moment ago with a single line: cat /etc/passwd | wc -l However, now that you understand how named pipes work, think about how valuable they might be to a programmer whose work requires interprocess communication. All he has to do is have a program create a named pipe, which can then be used as often as necessary to pass data from one process to another. Once the work is done, the program can remove the pipe. Simple, easy and dependable, with no need to create intermediate files to hold transient data.
Proc files are pseudo files that provide a simple way to examine many types of system information, directly from the kernel, without having to use complicated programs to ferret out the data. The original proc filesystem was developed to extract information about processes(*); hence the name "proc". * Footnote As I mentioned in Chapter 6, the idea of a process is fundamental to Unix. Indeed, within a Unix system, every object is represented by either a file or a process. In simple terms, files hold data or allow access to resources; processes are programs that are executing. A more precise definition of a process (also from Chapter 6) is: a program that is loaded into memory and ready to run, along with the program's data and the information needed to keep track of the program. All proc files are kept in the /proc directory. Within this directory, you will find a subdirectory for each process on the system. The names of the subdirectories are simply the process IDs of the various processes. (As we will discuss in Chapter 26, each process has a unique identification number called a "process ID".) For example, let's say that right now, one of the processes on your system is #1952. Information about that process can be found in pseudo files within the /proc/1952 directory. The idea for the /proc directory was taken from the Plan 9 operating system(*), a research project that ran from the mid-1980s to 2002. The Plan 9 project was established at Bell Labs by the same group that created Unix, C and C++. One of the basic concepts in Plan 9 was that all system interfaces should be considered to be part of the filesystem. In particular, information about processes was to be found in the /proc directory. Although Plan 9 was not a success, the idea of accessing many types of information as files was compelling and, in time, was widely adopted by the Unix and Linux communities. * Footnote The name Plan 9 came from an extremely hokey science fiction movie Plan 9 From Outer Space, generally considered to be the worst movie ever made. Why would a group of highly skilled, visionary computer scientists name a major project after such a movie? All I can say is that it's a geek joke. Linux, however, not only adopted /proc, but expanded it enormously. Modern Linux systems use this directory to hold many other pseudo files, affording access to a large variety of kernel data. In fact, if you are superuser, it is even possible to change some of the Linux kernel values by writing to a proc file. (Don't try it.) Figure 23-3 shows the most interesting proc files used by Linux. You can display the information in these files in the same way as you would display the contents of an ordinary text file. For example, to display information about your processor, use either of the following commands:
cat /proc/cpuinfo
Figure 23-3: The most interesting Linux proc files Proc files are pseudo files that are used to access kernel information. Such files are mostly used by system programs. Although you will rarely use proc files directly, there are a few that it is interesting to know about. See text for details. | |||||||||||||||||||||||||||||||||||||||||||||
|
|
Normally, you will never need to look at a proc file unless you are a system administrator. For the most part, proc files are used only by programs that need highly technical information from the kernel. For example, in Chapter 26, we will discuss the ps (process status) program that shows you information about the processes on your system. The ps program gathers the data it needs by reading the appropriate proc files. There is one particularly intriguing proc file that I did not list in Figure 23-3: /proc/kcore. This file represents the actual physical memory of your computer. You can display its size by using the ls program with the -l option (see Chapter 24): ls -l /proc/kcore The file will look huge: in fact, it will be the same size as all the memory (RAM) in your computer. Remember, though, this is a pseudo file: it doesn't really take up space. — hint — Linux users: I encourage you to explore the proc files on your system. Looking inside these files can teach you a lot about how your system is configured and how things works. To avoid trouble, make sure you are not superuser, even if you are just looking.
In the next few sections, we will talk about the Unix filesystem and how it is organized. In our discussions, I will use the standard Linux filesystem as an example. The details can vary from one Unix system to another, so it is possible that your system will be a bit different from what you read here. The basic ideas, however, including most of the directory names, will be the same. A typical Unix system contains well over 100,000 files(*) stored in directories and subdirectories. All these files are organized into a FILESYSTEM in which directories are organized into a tree structure based on a single main directory called the "root directory". The job of a filesystem is to store and organize data, and to provide access to the data to users and programs. You can see a diagram of a filesystem organization in Figure 23-4. The root directory is — directly or indirectly — the parent of all other directories in the system. * Footnote No, I am not exaggerating. Some basic Unix systems come with over 200,000 files. To estimate the number of files and directories on your system, run the following command as superuser: ls -R / | wc -l |
| |||||||
|
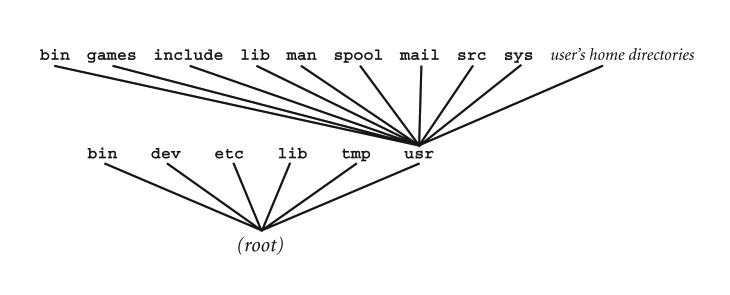
The first time you look at the organization of the Unix filesystem, it can be a bit intimidating. After all, the names are strange and mysterious, and very little makes sense. However, like most of the Unix world, once you understand the patterns and how they work, the Unix filesystem is easy to understand. Later in the chapter, we'll go over the subdirectories in Figure 23-4, one at a time. At the time, I'll explain how they are used and what the names mean. Before we start, however, I'd like to take a moment to talk about how the Unix filesystem came to be organized in this way. As we discussed in Chapter 2, the first Unix system was developed in the early 1970s at Bell Labs. Figure 23-5 shows the structure of the original Unix system, which was designed as a hierarchical tree structure. Don't worry about the names, they will all make sense later. All I want you to notice is that the original filesystem looks very much like a subset of the current filesystem (Figure 23-4). |
| |||||||
|
As Unix evolved over the years, the organization of the filesystem was changed to reflect the needs and preferences of the various Unix developers. Although the basic format stayed the same, the details differed from one version of Unix to another. This created a certain amount of confusion, especially when users moved between System V Unix and BSD (see Chapter 2). In the 1990s, the confusion increased when the creators of various Linux distributions began to introduce their own variations. In August 1993, a group of Linux users formed a small organization to develop a standard Linux directory structure. The first such standard was released in February 1994. In early 1995, the group expanded their goal when members of the BSD community joined the effort. From then on, they would devote themselves to creating a standard filesystem organization for all Unix systems, not just Linux. The new system was called the FILESYSTEM HIERARCHY STANDARD or FHS. Of course, since there are no Unix police, the standard is voluntary. Still, many Unix and Linux developers have chosen to adopt most of the FHS. Although many Unix systems differ from the FHS in some respects, it is a well thought-out plan, and it does capture the essence of how modern Unix and Linux filesystems are organized. If you understand the FHS, you will find it easy to work with any other Unix system you may encounter. For this reason, as we discuss the details of the Unix filesystem, I will use the FHS as a model. If you want to see what the basic FHS looks like, take a look at Figure 23-4. — hint — As you can see in Figure 23-4, all directories except the root directory lie within another directory. Thus, technically speaking, all directories except the root directory are subdirectories. In day-to-day speech, however, we usually just talk about directories. For example, we might refer to the "/bin directory". It is only when we want to emphasize that a particular directory lies within another directory, that we use the term "subdirectory", for example, "/bin is a subdirectory of the root directory."
From the very beginning, the Unix filesystem has been organized as a tree. In Chapter 9, we discussed trees as abstract data structures and, at the time, I explained that the main node of a tree is called the root (see Chapter 9 for the details). For this reason, we call the main directory of the Unix filesystem the ROOT DIRECTORY. Since the root directory is so important, its name must often be specified as part of a command. It would be tiresome to always have to type the letters "root". Instead, the root directory is indicated by a single / (slash). Here is a simple example. To list the files in a specific directory, you use the ls program (Chapter 24). Just type ls followed by the name of the directory. The command to list all the files in the root directory is: ls / When you specify the name of a directory or file that lies within the root directory, you write a / followed by the name. For example, within the root directory, there is a subdirectory named bin. To list all the files in this directory, you use the command: ls /bin Formally, this means "the directory named bin that lies within the / (root) directory". To indicate that a directory or file lies within another directory, separate the names with a /. For example, within the /bin directory, you will find the file that contains the ls program itself. The formal name for this file is /bin/ls. Similarly, within the /etc directory, you will find the Unix password file, passwd (see Chapter 11). The formal name for this file is /etc/passwd. When we talk about such names, we pronounce the / character as "slash". Thus, the name /bin/ls is pronounced "slash-bin-slash-L-S". — hint — Until you get used to the nomenclature, the use of the / character can be confusing. This is because / has two meanings that have nothing to do with one another. At the beginning of a file name, / stands for the root directory. Within a file name, / acts as a delimiter. (Take a moment to think about it.) What's in a Name? root In Chapter 4, I explained that, to become superuser, you log in with a userid of root. Now you can see where the name comes from: the superuser userid is named after the root directory, the most important directory in the filesystem.
In a Unix filesystem, hundreds of thousands of files are organized into a very large tree, the base of which is the root directory. In most cases, all the files are not stored on the same physical device. Rather, they are stored on a number of different devices, including multiple disk partitions. (As I explained earlier, each disk partition is considered a separate device.) Every storage device has its own local filesystem, with directories and subdirectories organized into a tree in the standard Unix manner. Before a local filesystem can be accessed, however, its tree must be attached to the main tree. This is done by connecting the root directory of the smaller filesystem to a specific directory in the main filesystem. When we connect a smaller filesystem in this way, we say that we MOUNT it. The directory in the main tree to which the filesystem is attached is called the MOUNT POINT. Finally, when we disconnect a filesystem, we say that we UNMOUNT it. Each time a Unix system starts, a number of local filesystems are mounted automatically as part of the startup process. Thus, by the time a system is running and ready to use, the main filesystem has already been augmented by several other filesystems. From time to time, you may have to mount a device manually. To do so, you use the mount program. To unmount a device, you use umount. As a general precaution, only the superuser is allowed to mount a filesystem. However, for convenience, some systems are configured to allow ordinary users to mount certain pre-set devices, such as CDs or DVDs. Here is an example of a mount command. In this example, we mount the floppy drive filesystem found on device /dev/fd0, attaching it to the main tree at the location /media/floppy: mount /dev/fd0 /media/floppy The effect of this command is to enable users to access the files on the floppy via the /media/floppy directory. Mounting and unmounting are system administration tasks that require superuser status, so I won't go into the details. Instead, I will refer you to the online manual (man mount). As an ordinary user, however, you can display a list of all the filesystems currently mounted on your system, by entering a mount command by itself: mount Broadly speaking, there are two types of storage devices: FIXED MEDIA, such as hard drives, are attached to the computer permanently. REMOVABLE MEDIA can be changed while the system is running: CDs, DVDs, floppy disks, tapes, flash drives, memory cards, and so on. At the system level, the distinction is important because if there is a chance that a filesystem might literally disappear, Unix must make sure that it is managed appropriately. For example, before you can be allowed to a eject a CD, Unix must ensure that any pending output operations are complete. For this reason, the Filesystem Hierarchy Standard mandates specific directories to use for mounting filesystems. For fixed media that are not mounted elsewhere (such as extra hard disks), the directory is /mnt; for removable media, the directory is /media. What's in a Name? Mount, Unmount In the early days of Unix (circa 1970), disk drives were large, expensive devices that, by today's standards, held relatively small amounts of data (40 megabytes at best). Unlike modern hard drives which are complete units, the older disk drives used removable "disk packs", each of which had its own filesystem. Whenever a user needed to change a disk pack, the system administrator had to physically unmount the current disk pack and mount the new one. This is why, even today, we talk about "mounting" and "unmounting" a filesystem. When we use the mount program, we are performing the software equivalent of mounting a disk pack in a drive.
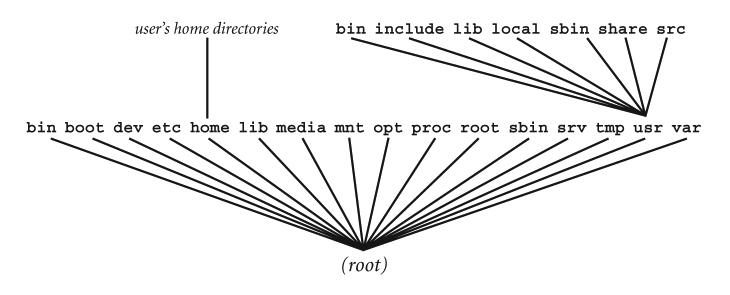
The fastest way to cultivate a basic understanding of the filesystem on your computer is to look in the root directory and examine all the subdirectories. These directories form the backbone of the entire system. As such, they are sometimes referred to as TOP-LEVEL DIRECTORIES. Figure 23-6 summarizes the standard contents of the root directory as specified by the Filesystem Hierarchy Standard (FHS) we discussed earlier in the chapter. Although the details vary from one Unix system to another, all modern filesystems can be considered to be variations of the FHS. Thus, once you understand the FHS, you will be able to make sense out of any Unix filesystem you happen to encounter. Figure 23-6: Contents of the root directory The skeleton of the Unix filesystem is created by the top-level directories, that is, the subdirectories of the root directory. Here is a list of all the top- level directories mandated by the Filesystem Hierarchy Standard (FHS). Since some Unix and Linux systems do not follow the FHS exactly, you may find variations from what you see here. Still, you can use this list is as a starting point from which to understand your own system.
Our goal here is to start with the root directory and work our way through the list of top-level directories. As we discuss each directory, you can check it out on your system by using the ls program (Chapter 24). For example, to display the contents of the /bin directory, use one of the following commands:
ls /bin
When you use ls with no options, you will see only file names. If you use the -l (long) option, you will see extra details. If there is too much output, and it scrolls by too fast, you can display it one screenful at a time by piping it to less (Chapter 21):
ls -l / | less
Root directory
/bin
/boot
ls -l /boot | less
If you have updated your system, you will find more than one version of the kernel. In most cases, the one in use is the latest one, which you can identify by looking at the name. (The version number will be part of the name.)
/dev
/etc
/home
/lib
/lost+found
/media
/mnt
/opt
/root
/sbin
/srv
/tmp
/usr
/var
What's in a Name? dev, etc, lib, mnt, opt, src, srv, tmp, usr, var There is a Unix tradition to use 3-letter names for the top-level directories of the filesystem. The reason is that such names are short and easy to type. However, when we talk, these names can be awkward to pronounce. For this reason, each 3-letter name has a preferred pronunciation.
dev: "dev"
As a general rule, if you are talking about something Unix-related and you come across a name with missing letter or two, put it in when you pronounce the name. For example, the name of the /etc/passwd file is pronounced "slash et-cetera slash password". The file /usr/lib/X11 is pronounced "slash user slash libe slash x-eleven" You will sometimes hear people say that etc stands for "extended tool chest", or that usr means "Unix system resources", and so on. None of these stories are true. All of these names are abbreviations, not acronyms.
As we discussed earlier, the /usr and /var directories are mount points for separate filesystems that are integrated into the main filesystem. The /usr filesystem is for static data; /var is for variable data. Both these directories hold system data, as opposed to user data which is kept in the /home directory. In addition, both these directories contain a number of standard subdirectories. However, the /var filesystem is more for system administrators, so it's not that important to ordinary users. The /usr filesystem, on the other hand, is much more interesting. It contains files that are useful to regular users and to programmers. For this reason, I'll take you on a short tour of /usr, showing you the most important subdirectories as described in the Filesystem Hierarchy Standard. For reference, Figure 23-7 contains a summary of these directories. As we discussed earlier, you may notice some differences between the standard layout and your system. Figure 23-7: Contents of the /usr directory The /usr directory is the mount point for a secondary filesystem that contains static data of interest to users and programmers. Here are the most important subdirectories you will find within this directory, according to the Filesystem Hierarchy Standard. See text for details.
/usr/bin
/usr/games
/usr/include
/usr/lib
/usr/local
/usr/sbin
/usr/share
/usr/src
/usr/X11
As we have discussed, two different directories are used to hold general-use executable programs: /bin and /usr/bin. You might be wondering, why does Unix have two such directories? Why not simply store all the programs in one directory? The answer is: the two bin directories are a historical legacy. In the early 1970s, the first few versions of Unix were developed at Bell Labs on a PDP 11/45 minicomputer (see Chapter 2). The particular PDP 11/45 used by the Unix developers had two data storage devices. The primary device was a fixed-head disk, often called a drum. The drum was relatively quick, because the read- write head did not move as the disk rotated. However, data storage was limited to less than 3 megabytes. The secondary device was a regular disk called an RP03. The read-write head on the RP03 disk moved back and forth from one track to another, which allowed it to store much more data, up to 40 megabytes. However, because of the moving head, the disk was a lot slower than the drum. In order to accommodate multiple storage devices on a single computer, the Unix developers used a design in which each device had its own filesystem. The main device (the drum) held what was called the root filesystem; the secondary device (the disk) held the what was called the usr filesystem. Ideally, it would have been nice to keep the entire Unix system on the drum, as it was a lot faster than the disk. However, there just wasn't enough room. Instead, the Unix developers divided all the files into two groups. The first group consisted of the files that were necessary for the startup process and for running the bare-bones operating system. These files were stored on the drum in the root filesystem. The rest of the files were stored on the disk in the usr filesystem. At startup, Unix would boot from the drum. This gave the operating system immediate access to the essential files in the root filesystem. Once Unix was up and running, it would mount the usr filesystem, which made it possible to access the rest of the files. Each of the two filesystems had a bin directory to hold executable programs. The root filesystem had /bin, and the usr filesystem had /usr/bin. During the startup process, before the usr filesystem was mounted, Unix only had access to the relatively small storage area of the root filesystem. For this reason, essential programs were stored in /bin; other programs were stored in /usr/bin. Similarly, library files were divided into two directories, /lib and /usr/lib, and temporary files were kept in /tmp and /usr/tmp. In all cases, the root filesystem held only the most important files, the files necessary for booting and troubleshooting. Everything else went in the usr filesystem. Today, storage devices are fast, inexpensive, and hold large amounts of data. For the most part, there is no compelling reason to divide the core of Unix into more than one filesystem stored on multiple devices. Indeed, some Unix systems put all the general-use binary files in one large directory. Still, many Unix systems do use separate filesystems combined into a large tree. We will discuss the reasons for such a design later in the chapter, when we talk about the virtual filesystem. As a general rule, modern Unix systems distinguish between three types of software: general-use programs that might be used by anyone; system administration programs used only by the superuser; and large, third- party application programs that require many files and directories. As we discussed earlier in the chapter, the three different types of programs are stored in their own directories. For reference, Figure 23-8 summarizes the various locations where you will find Unix program files. Figure 23-8: Directories that hold program files The Unix filesystem has a number of different locations for program files. General-use programs are stored in directories with the name bin ("binary files"). System administration programs are stored in directories named sbin ("system binaries"). Large third-party applications are stored in directories named opt ("optional software"). Programs are further categorized as being either essential or non-essential. Essential programs are necessary to start the system or perform crucial system administration. Everything else is non-essential. The details you see here are based on the Filesystem Hierarchy Standard. Your system may differ somewhat.
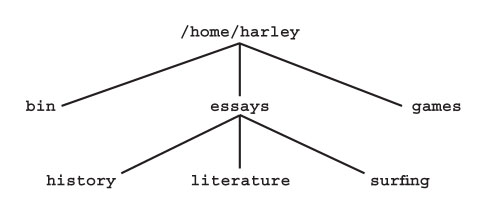
With so many system directories chock-full of important files, it is clear that we need an orderly system to control where users store their personal files. Of course, people as intelligent as you and me wouldn't make a mess of things if we were allowed to, say, store our own personal programs in the /bin directory, or our own personal data files in /etc. But for the most part, we can't have the hoi polloi putting their files, willy-nilly, wherever they want — we need organization. The solution is to give each user his own HOME DIRECTORY, a directory in which he can do whatever he wants. When your Unix account was created (see Chapter 4), a home directory was created for you. The name of your home directory is kept in the password file (Chapter 11) and when you log in, the system automatically places you in this directory. (The idea of being "in" a directory will make more sense after you have read Chapter 24.) Within your home directory, you can store files and create other subdirectories as you see fit. Indeed, many people have large elaborate tree structures of their own, all under the auspices of their own home directory. The Filesystem Hierarchy Standard suggests that home directories be created in the /home directory. On small systems, the name of a home directory is simply the name of the userid, for example, /home/harley, /home/linda, and so on. On large systems with many userids, there may be an extra level of subdirectories to organize the home directories into categories. For example, at a university, home directories may be placed within subdirectories named undergrad, grad, professors and staff. At a real estate company, you might see agents, managers and admin. You get the idea. The only userid whose home directory is not under /home is the superuser's (root). Because the administrator must always be able to control the system, the superuser's home directory must be available at all times, even when the system is booting or when it is running in single-user mode (see Chapter 6). On many systems, the /home directory is in a secondary filesystem, which is not available until it is mounted. The /root directory, on the other hand, is always part of the root filesystem and, thus, is always available. Each time you log in, the environment variable HOME is set to the name of your home directory. Thus, one way to display the name of your home directory is to use the echo program to display the value of the HOME variable: echo $HOME (The echo program simply displays the values of its arguments. It is discussed, along with environment variables, in Chapter 12.) As a shortcut, the symbol ~ (tilde) can be used as an abbreviation for your home directory. For example, you can display the name of your home directory by using: echo ~ Whatever its name, the important thing about your home directory is that it is yours to use as you see fit. One of the first things you should do is create a bin subdirectory to store your own personal programs and shell scripts. You can then place the name of this directory — for example, /home/harley/bin — in your search path. (The search path is a list of directories stored in the PATH environment variable. Whenever you enter the name of a program that is not built into the shell, Unix looks in the directories specified in your search path to find the appropriate program to execute. See Chapter 13 for the details.) Figure 23-9 shows a typical directory structure based on the home directory of /home/harley. This home directory has three subdirectories: bin, essays and games. The essays directory has three subdirectories of its own: history, literature and surfing. All of these directories contain files which are not shown in the diagram. As you will see in Chapter 24, making and removing subdirectories is easy. Thus, it is a simple matter to enlarge or prune your directory tree as your needs change. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
The /home directory is part of the Filesystem Hierarchy Standard, and is widely used on Linux systems. If you use another type of Unix, however, you may find your home directory in a different place. The classical setup — used for many years — was to put home directories in the /usr directory. For example, the home directory for userid harley would be /usr/harley. Other systems use /u, /user (with an "e"), /var/home or /export/home. For reference, here are examples of home directory locations you might see on different systems:
/usr/harley
On large systems, especially those where files are stored on a network, the exact location of the home directories may be more involved; much depends on how the system administrator has decided to organize the filesystem. For example, I have an account on one computer where my home directory is sub-sub-sub-sub- subdirectory: /usr/local/psa/home/vhosts/harley — hint — On any system, you can find out the location of your home directory by entering either of the following commands:
echo $HOME
In this chapter, you and I have covered a lot of material. To the extent that you care about such things, the details will be more or less interesting. However, there is a lot more to this forest than the leaves on the trees. The Unix filesystem was created by a few very smart people and, over the years, enhanced through the efforts of a great many experienced programmers and system administrators. The end-product is not only utilitarian, but beautiful. In this section, I want to help you appreciate, not only the usefulness of the system, but its beauty. To do so, I'm going to explain how multiple filesystems residing on a variety of different storage devices are combined into one large tree-structured arrangement. Earlier in the chapter, I explained that every storage device has its own local filesystem, with directories and subdirectories organized into a tree in the standard Unix manner. Before you can access such a filesystem, it must be connected to the main filesystem, a process we call mounting. In technical terms, we mount a filesystem by connecting its root directory to a mount point, a directory within the main filesystem. I want you to notice that when we talk about these ideas, we use the word "filesystem" in two different ways. Don't be confused. First, there is the "Unix filesystem", the large, all-inclusive structure that contains every file and every directory in the entire system. Second, there are the smaller, individual "device filesystems" that reside on the various storage devices. The Unix filesystem is created by connecting the smaller device filesystems into one large structure. To explain how it all works, I need to start at the beginning by answering the question, what happens when the system boots? When you turn on your computer, a complicated series of events are set into motion called the boot process (described in Chapter 2). After the power-on self-test, a special program called the boot loader takes control and reads data from the BOOT DEVICE in order to load the operating system into memory. In most cases, the boot device is a partition on a local hard drive. However, it can also be a network device, a CD, a flash drive, and so on. Within the data on the boot device lies the initial Unix filesystem called the ROOT FILESYSTEM. The root filesystem, which is mounted automatically, holds all the programs and data files necessary to start Unix. It also contains the tools a system administrator would need should something go wrong. As such, the root filesystem contains, at minimum, the following directories (which are discussed earlier in the chapter): /bin /boot /dev /etc /lib /root /sbin /tmp Once the root filesystem is mounted and the kernel has been started, other device filesystems are mounted automatically. The information about such filesystems is kept in a configuration file, /etc/fstab(*), which can be modified by the system administrator. (The name stands for "file system table".) To look at the file on your system, use the command: less /etc/fstab * Footnote On Solaris, the file is named /etc/vfstab. The root filesystem is always stored on the boot device. However, there are three other filesystems that may reside on separate devices: usr, var and home. If these filesystems are on their own devices, they are connected to the Unix filesystem by attaching them to the appropriate subdirectories. The usr filesystem is mounted at /usr; the var filesystem is mounted at /var; and so on. This is all done automatically so, by the time you see the login prompt, everything has been mounted and the Unix filesystem is up and running. Each device uses a filesystem appropriate for that type of device. A partition on a hard drive uses a filesystem suitable for a hard drive; a CD-ROM uses a filesystem suitable for CD-ROMs, and so on. As you would imagine, the details involved in reading and writing data vary significantly depending on the type of device. They vary depending on whether the filesystem is local (on your computer) or remote (on a network). Finally, some filesystems — such as procfs for proc files — use pseudo files, which do not reside on storage devices. For reference, Figure 23-10 contains a list of the filesystems you are most likely to encounter. Figure 23-10: The most common filesystems For reference, here are the most common filesystems you will encounter when using a Unix or Linux system. Disk-based filesystems store data on hard disks, CDs, DVDs or other devices; network filesystems support the sharing of resources over a network; special-purpose filesystems provide access to system resources, such as pseudo files.
The significant differences among the various filesystems raises an important question. Consider the following two cp (copy) commands:
cp /media/cd/essays/freddy-the-pig /home/harley/essays
We'll talk about cp in Chapter 25. For now, all I want you to appreciate is that the first command copies a file from a directory on a CD, to a directory on a hard disk partition. The second command copies information from a pseudo file (which is generated by the kernel) to a file on a hard disk partition. In both cases, you just enter a simple command, so who takes care of the details? The details are handled by a special facility called the VIRTUAL FILE SYSTEM or VFS. The VFS is an API (application program interface) that acts as a middleman between your programs and the various filesystems. Whenever a program requires an I/O operation, it sends a request to the virtual file system. The VFS locates the appropriate filesystem and communicates with it by instructing the device driver to perform the I/O. In this way, the VFS allows you and your programs to work with a single, uniform tree- structure (the Unix filesystem) even though, in reality, the data comes from a variety of separate heterogeneous filesystems. In our first example, data must be read from the CD. The cp program issues a read request which is handled by the virtual file system. The VFS sends its own request to the CD filesystem. The CD filesystem sends the appropriate commands to the CD device driver, which reads the data. In this way, neither you nor your programs need to know any of the details. As far as you are concerned, the Unix filesystem exists exactly as you imagine it and works exactly the way you want it to work. Can you see the beauty? At one end of every file operation, the virtual file system talks to you in your language. At the other end, the VFS talks to the various device filesystems in their own languages. As a result, you and your programs are able to interact with any of the filesystems without having to communicate with them directly. Now consider another question. Whenever a new type of filesystem is developed (say, for a new device), how can it be made to work with Unix? The answer is conceptually simple. All the developers of the new device have to do is teach the new filesystem to speak "VFS" language. This enables the filesystem to join the world of Unix, where it will fit in seamlessly. Here is the beautiful part: No matter when you learned Unix — 35 years ago or 35 minutes ago — the Unix filesystem looks and works the same way. Moreover, as new devices and better filesystems are developed over the years, they are integrated into your world smoothly and easily. This is the reason why an operating system that was designed at a time when students were wearing love beads and protesting the war, still works well at a time when students are wearing mobile phones and protesting the war. And what about the future? We don't know what kind of strange new devices and information sources will become available in the years to come. After all, when it comes to technology, no one can make promises. What I can promise you, however, is that no matter what new technology comes along, it will work with Unix. And I can also promise you that, years from now, you will be teaching Unix to your children(*). * Footnote So save this book.
Review Question #1: What is a Unix file? What are the three main types of files? Describe each type. Review Question #2: Explain the difference between a text file and a binary file. Give three examples of each. Review Question #3: What is the Filesystem Hierarchy Standard or FHS? Within the FHS, briefly describe the contents of: 1. The root directory (/) 2. The following top-level directories: /bin /boot /dev /etc /home /lib /sbin /tmp /usr /varReview Question #4: Within the FHS which directories contain general-use programs? Which directories contain system administration programs? Review Question #5: What is a home directory? Within the FHS where do you find the home directories? What is the only userid whose home directory is in a different place? Why? Suppose your userid is weedly and you are an undergraduate student at a large university. Give two likely names for your home directory. Applying Your Knowledge #1: The following command will list all the subdirectories of the root directory: ls -F / | grep '/' Use this command to look at the names of the top-level directories on your system. Compare what you see to the basic layout of the Filesystem Hierarchy Standard. What are the differences? Applying Your Knowledge #2: As we will discuss in Chapter 24 you can use the cd to change from one directory to another and ls to list the contents of a directory. For example to change to the /bin directory and list its contents you can use: cd /bin; ls Explore your system and find out where the following files are stored:
• Users' home directories
Hint: You may find the whereis program useful (see Chapter 25). Applying Your Knowledge #3: Enter the following command: cp /dev/tty tempfile Type several lines of text and then press ^D. What did you just do? How did it work? Hint: To clean up after yourself you should enter the following command to remove (delete) the file named tempfile: rm tempfile For Further Thought #1: Unix defines a "file" a very general way. Give three advantages to such a system. Give three disadvantages. For Further Thought #2: There is no uniformity as to how closely Unix systems must follow the Filesystem Hierarchy Standard. Some systems stick fairly close to the ideal; others are significantly different. Would it be a good or a bad idea to require all Unix systems to use the same basic filesystem hierarchy? Discuss the advantages and the disadvantages.
List of Chapters + Appendixes
© All contents Copyright 2026, Harley Hahn
| |||||||||||||||||||||||||||||||||||||||